Last updated on 2025-12-9…
模型发布概览
| 版本 | LLaMA 1 | LLaMA 2 | LLaMA 3 | LLaMA 4 |
|---|---|---|---|---|
| 发布日期 | 2023年2月 | 2023年7月 | 2024年4月 | 2025年4月5日 |
| 参数规模 | 7B、13B、33B、65B | 7B、13B、70B(含Chat版) | 8B、70B、405B | Scout:17B活跃/109B总 Maverick:17B活跃/400B总 Behemoth:288B活跃/约2T总(即将发布) |
| 训练数据量 | 1.4万亿 token(公开数据) | 2万亿 token(更高质量、多样) | 15万亿 token(含大量代码+30+语言) | 30万亿 token(首次加入Meta内部用户数据) |
| 上下文长度 | 2K token | 4K token | 128K(部分变体支持1M) | Scout:1000万 token Maverick:100万 token |
| 词表大小 | 32K | 32K | 128K | 128K |
| 主要基准表现 | 13B在多项任务超越GPT-3(175B) | 接近或超过同期闭源模型 | 大幅领先同级别开源模型,逼近GPT-4 | Maverick在多语言、编码任务超越GPT-4o Scout长上下文表现极强 |
| 关键技术与特性 | 纯研究用途、高效证明概念 | 开源权重+商业许可、RLHF安全对齐 | 多语言(30+种)、超长上下文、驱动Meta全家桶产品 | MoE稀疏激活极致高效 原生多模态(图文输入→文本输出) 支持12种语言(数据量提升10倍) |
| 许可与可用性 | 仅限研究,禁止微调 | 开源可商用 | 开源可商用 | 开源可商用(最宽松版本) |
LLaMA模型的发展历程展现出一条稳步创新的轨迹,旨在提升LLM的效率、性能和通用性。
- 从LLaMA1 开始,它引入了诸如使用RMSNorm进行输入归一化和更平滑的激活函数等基础性变革,后续的每个版本都在此基础上进行了改进。
- LLaMA2 通过 GQA 优化推理效率,改进了这种方法,为 LLaMA3 的更大改进奠定了基础。
- LLaMA3 通过将 GQA 扩展到更小的模型、采用词汇量更大的更高效的分词器、将上下文长度加倍以及显著增加训练数据,扩展了这些功能。
- LLaMA 4 引入了 Mixture-of-Experts 架构与原生多模态能力,实现了行业领先的上下文长度(最高10M tokens)和在极高效率下的前沿多模态智能。
LLaMA1
LLaMA1是 Meta 开发的一个高效开源语言模型,在继承 Transformer 架构的基础上,LLaMA1 进行了一系列关键的技术改进,包括预归一化与RMSNorm、旋转位置编码(ROPE) 、SwiGLU激活函数等技术,这些改进显著提升了模型的性能和训练稳定性。
预归一化与RMSNorm
受 GPT3 架构中训练稳定性改进的启发,Llama 1 也对每个 Transformer 子层的输入进行归一化,而不仅仅是对输出进行归一化,如下图所示:
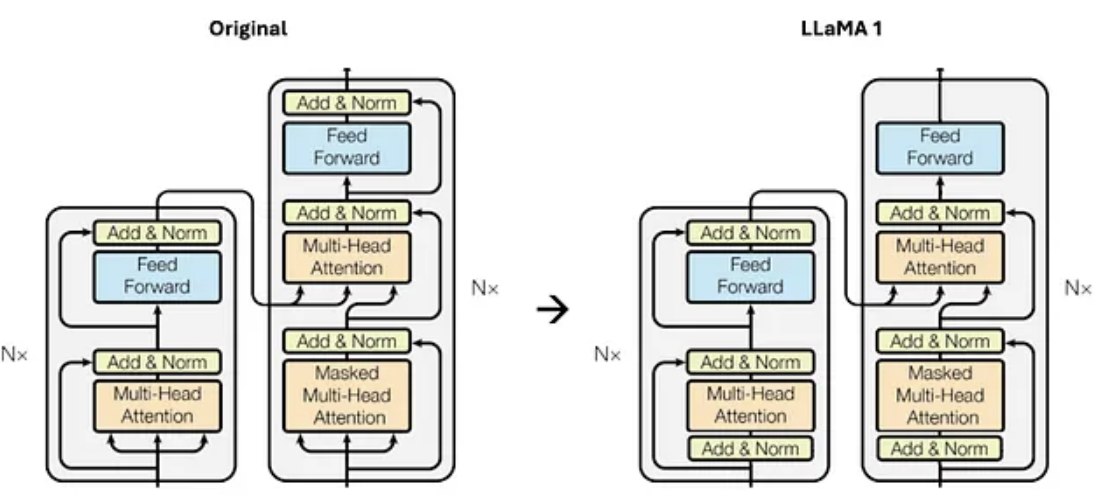
此外,使用 RMSNorm 代替了传统的 LayerNorm 函数,通过归一化向量的均方根值,而不需要中心化或依赖均值。
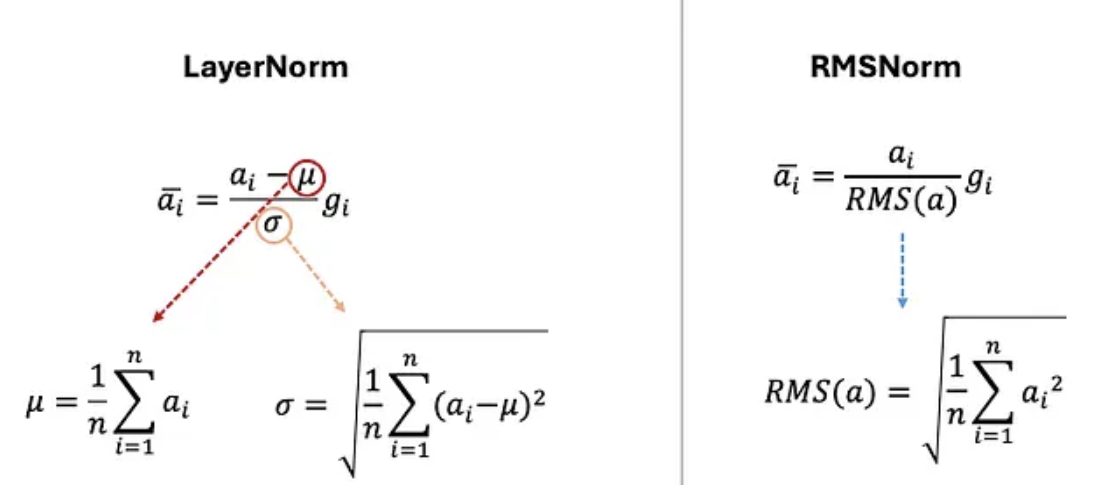
RMSNorm 之所以能取得更高的效率,是因为其作者证明了 LayerNorm 的优势源于重缩放不变性而非中心化不变性。这一发现使他们能够从归一化过程中移除均值计算,从而简化了流程,使其同样有效,并显著提高了效率。
旋转位置编码(RoPE)
位置嵌入对于语言学习模型(LLM)至关重要,因为Transformer架构具有顺序不变性。这意味着即使两个句子使用了相同的词语,但顺序不同且含义不同,Transformer也会以相同的方式表示它们。例如,如果不应用位置嵌入,以下句子对于Transformer来说含义相同:
- Sentence 1: Llama 2 is better than Llama 1
- Sentence 2: Llama 1 is better than Llama 2
原始论文(Attention Is All You Need)实现了绝对位置嵌入,该嵌入通过两个正弦函数(正弦和余弦)表示。序列中的每个位置都有一个唯一的位置嵌入,这些位置嵌入被加总到词嵌入中,从而确保包含相同词语的两个句子含义不同。
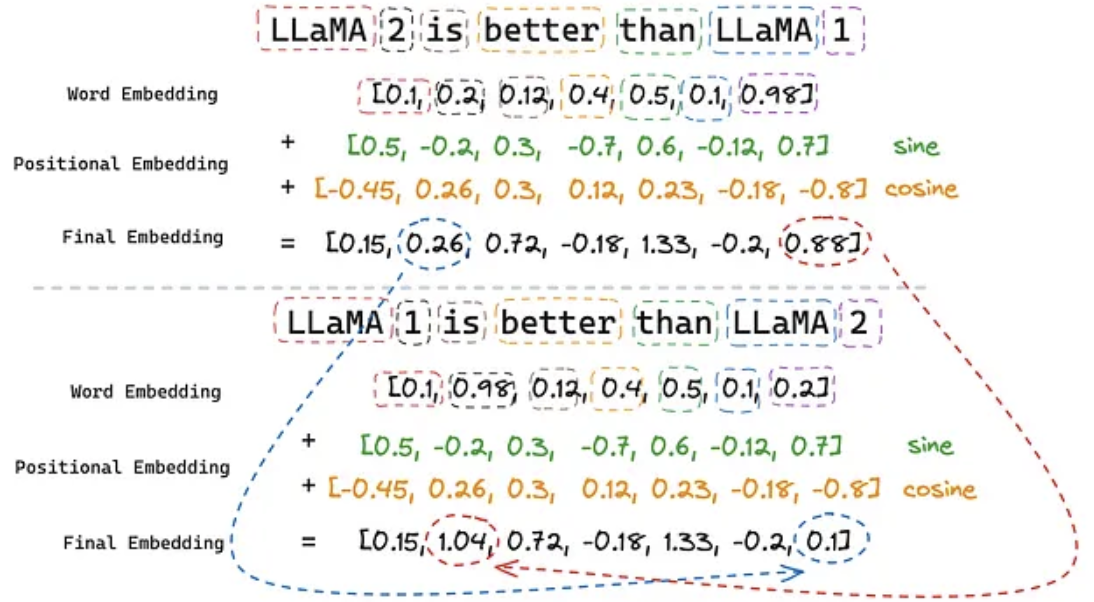
尽管它已经解决了Transformer模型顺序不变的问题,但它仍然创建彼此独立的嵌入位置。其结果是,两个位置之间的邻近性没有被建模。这意味着从模型的角度来看,位置1和2与位置1和500之间的相关性没有区别。我们知道实际情况并非如此,因为理论上,位置1和2中单词的相似度应该高于位置1和500中单词的相似度。
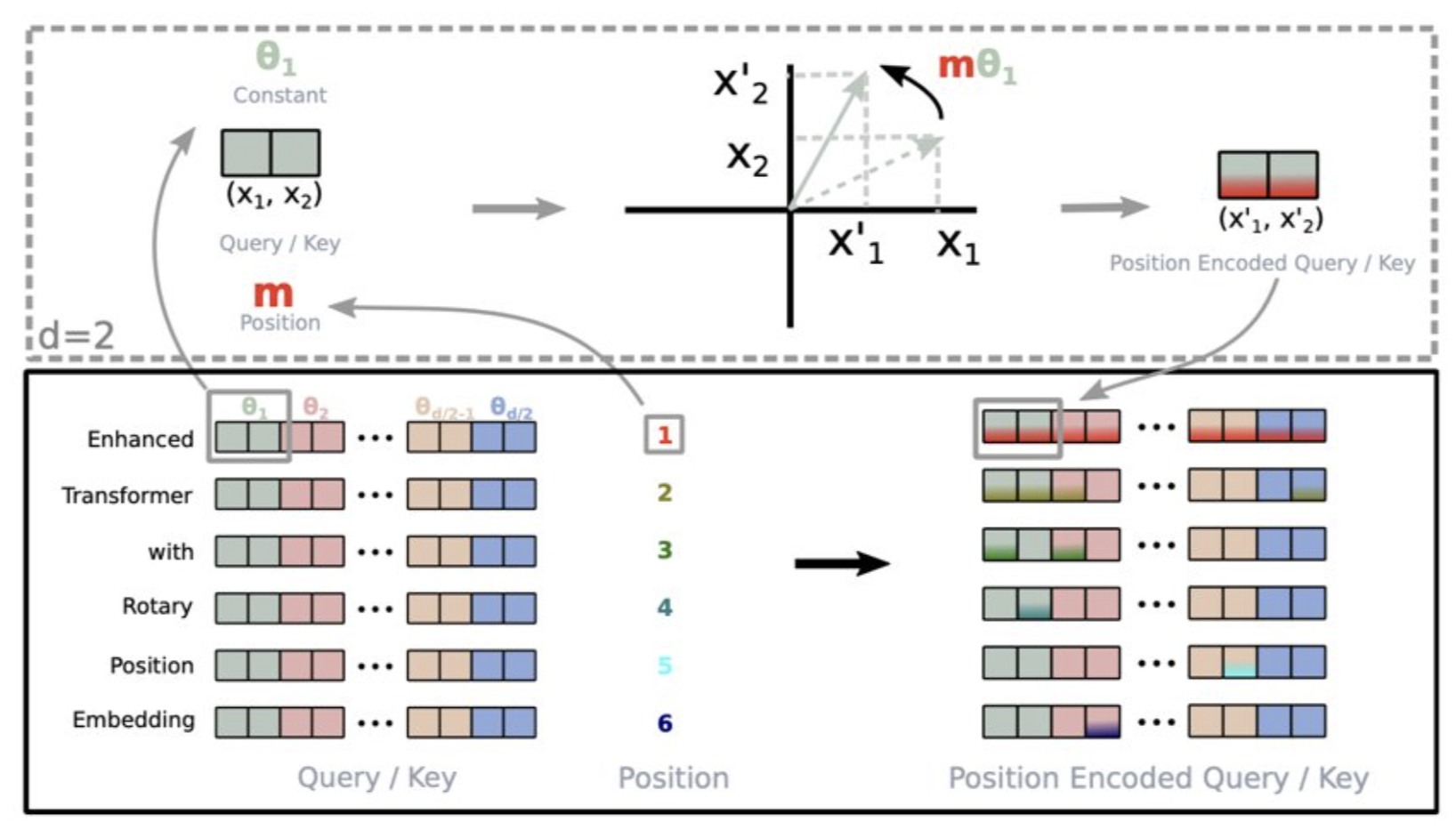
旋转位置嵌入(Rotary Position Embedding,RoPE)可以解决这个问题,它通过旋转词嵌入来表示序列中每个位置,从而对单词的相对位置进行建模。我们沿用之前的例子:“Llama 2 is better than Llama 1”,并假设词嵌入现在是二维的。单词“better”将由原始二维向量基于其位置 m(4) 和常数 θ 旋转得到的二维向量表示,如下图所示:
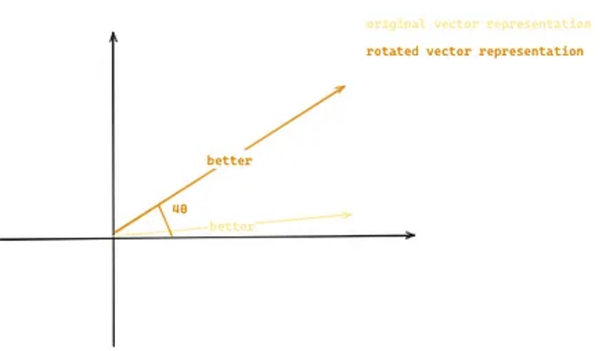
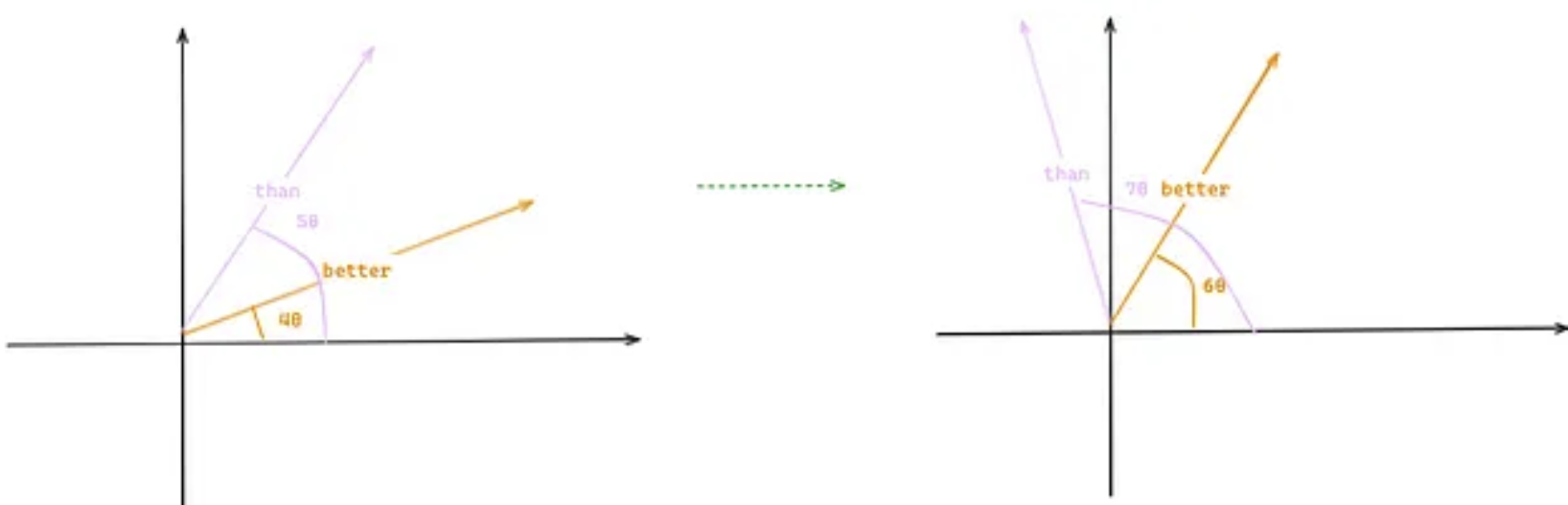
这种方法可以让我们保持词语之间的相对距离,因为即使我们在原句中添加更多词语,两个向量之间的相似度也保持不变。例如,假设我们在句子“Llama 2 is better than Llama 1”中添加两个词,其中“better”和“than”的位置不同(4 和 5 → 6 和 7),但由于旋转角度相同,两个向量之间的相似度也保持不变(左图中向量之间的点积与右图中的点积相同)。
SwiGLU 激活函数
SwiGLU(Swish-Gated Linear Unit)是一种结合非线性激活函数的门控单元激活机制,相比传统的 ReLU 函数,增强了激活函数的表达能力,使模型可以捕捉更复杂的模式。此外,SwiGLU 减少了梯度消失问题(ReLU 容易导致负值被切为0),从而提升训练稳定性和模型性能。

SwiGLU 与其他 GLU 变体对比:

论文中,SwiGLU 在 Transformer 语言模型任务上通常能比 ReLU / GELU 提供更好的困惑度(perplexity)。
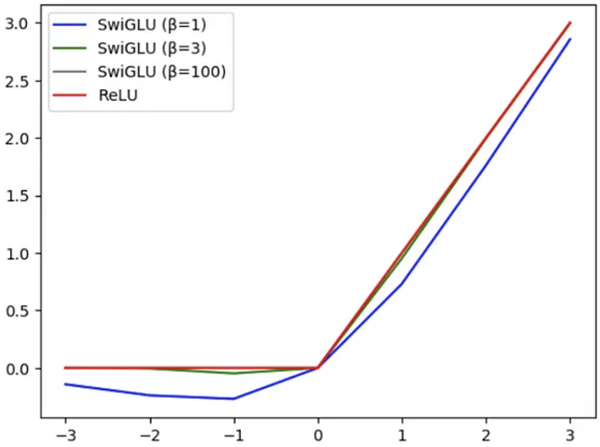
SwiGLU 具有一个可训练参数 β,用于控制插值程度。如图 4 所示,随着 β 值的增加,其行为越来越类似于 ReLU(当 β=100 时,ReLU 和 SwiGLU 重叠)。
LLaMA2
LLaMA2 的架构和 LLaMA1 没有太大的变化,只是多了分组查询注意力(GQA)。而且在上下文处理能力(将上下文长度从 2048 增加到 4096)、注意力机制优化、训练数据质量、性能表现、多语言支持和推理效率方面实现了全面改进,进一步缩小了开源模型与闭源大型模型之间的性能差距。
分组查询注意力(GQA)
GQA是一种优化多头注意力机制的方法,将Q的头数分组,减少计算复杂度。传统的多头注意力机制为每个注意力头生成独立的 Q,K,V,而 GQA 将查询头分为少数几组,共享 Q。
传统注意力公式是:
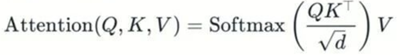
在 GOA中:Q被分为G组,每组共享相同的Q
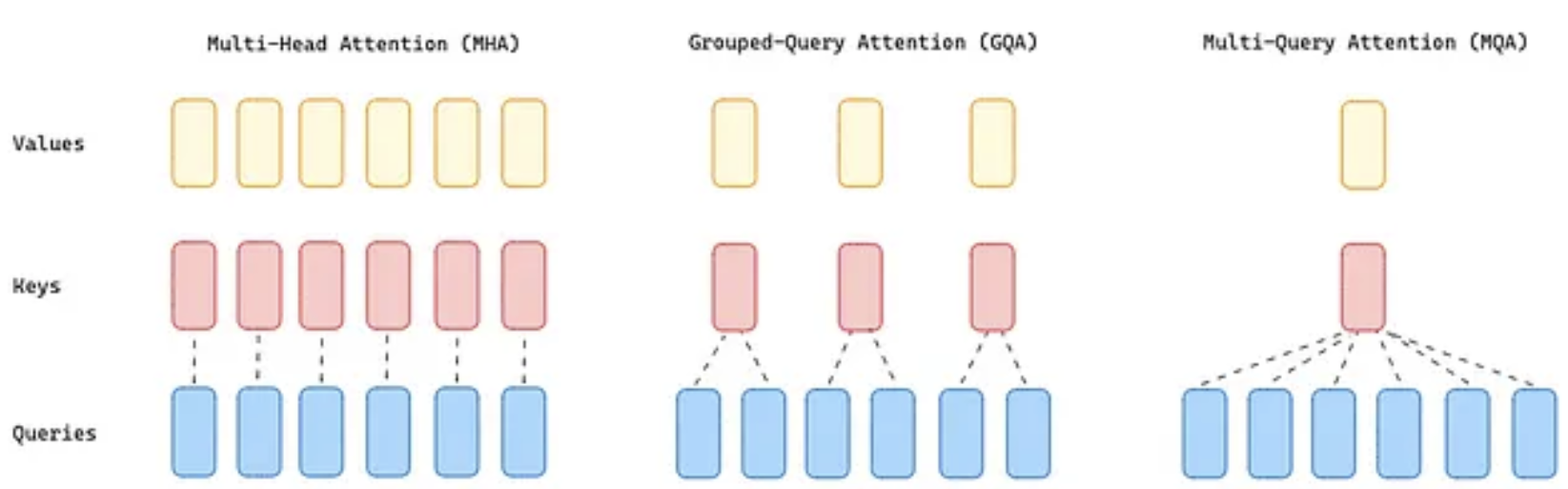
多查询注意力机制(MQA) 通过在注意力层中使用单个键值对但多个查询头,显著降低了内存需求。然而,这种方案可能会导致模型质量下降和训练不稳定,因此其他开源的层级模型(例如 T5)并未采用这种方法。
GQA 介于 MHA 和 MQA 之间,它将查询值分成 G 个组(GQA-G),每个组共享一个键值对。GQA-1 表示所有查询都聚合在一个组中,因此与 MQA 相同;而 GQA-H(H = 键值对数量)则等同于 MHA,其中每个查询都被视为一个组。这种方法将键值对的数量减少到每个查询组一个键值对。它减少了缓存的键值对的大小,从而减少了需要加载的数据量。与 MQA 相比,这种更为温和的缩减方式提高了推理速度,并在解码过程中降低了内存需求,同时保持了接近 MHA 的质量和几乎与 MQA 相同的速度。
LLaMA3
LLaMA3 的架构和 LLaMA1、2 没有太大的变化。Meta 的 LLaMA3 系列(2024 年发布)包括多个迭代版本,主要有 LLaMA 3(基础版)、LLaMA 3.1(扩展版)和 LLaMA 3.2(多模态版),后续还有 LLaMA 3.3(优化版)。这些版本在模型规模、训练数据、多语言支持、上下文长度和应用场景上逐步优化,旨在提升开源 LLM 的能力和可访问性。
| 属性 | LLaMA 3(2024.04) | LLaMA 3.1(2024.07) | LLaMA 3.2(2024.09) | LLaMA 3.3(2024.12/2025.01) |
|---|---|---|---|---|
| 模型规模 | 8B、70B | 8B、70B、405B | 1B、3B(轻量视觉)、11B、90B(多模态) | 70B(单一旗舰规模) |
| 训练数据量 | 15T token | 15T+ token(质量更高 + 合成数据) | 基于 3.1 + 大量图像-文本对 | 基于 3.1,进一步清洗 + 多语言优化 |
| 上下文长度 | 8K token | 128K token | 128K token | 128K token |
| 多语言支持 | 基础(以英语为主,8 种语言) | 8 种核心语言(英、法、德、西、意、葡、印地、泰) | 继承 3.1 多语言 | 同样 8 种语言,但质量显著提升 |
| 多模态能力 | 无 | 无 | 支持图像+文本输入 → 文本输出 | 无(纯文本) |
| 关键特性 | 高效、首次集成 Meta 全家桶 | 405B 旗舰、工具调用、合成数据蒸馏 | 轻量版可在手机运行、视觉理解 | 指令跟随最强、性能接近 3.1 405B |
| 代表性基准 | 8B MMLU 68.4% 70B MMLU 82.0% |
405B MMLU 88.6% GSM8K 96.8% |
视觉任务领先,文本能力 ≈ 3.1 70B | MMLU ≈86%,IFEval 指令跟随第一 |
| 推荐场景 | 入门级部署、原型开发 | 长上下文、复杂推理、代码生成、工具代理 | 移动端、边缘设备、图文问答、文档理解 | 多语言客服、成本敏感的高性能商用部署 |
| 许可 | 开源商用(Llama 3 Community License) | 开源商用(同上,支持模型蒸馏) | 开源商用 | 开源商用(最宽松条款) |
| 官方论文/博客 | Llama 3 | Llama 3.1 | Llama 3.2 | Llama 3.3 技术报告 |
LLaMA4
https://www.lapis.cafe/posts/ai-and-deep-learning/llama-4-report/
全面转向MoE架构
LLaMA4 系列是 Meta 首次在旗舰模型中采用专家混合 (MoE, Mixture of Experts) 架构。与传统的“稠密”模型(每次计算都使用所有参数)不同,MoE 模型包含多个“专家”网络,对于每个输入(token),系统会动态地选择一小部分专家来处理。
MoE 架构的核心优势在于计算效率。在 LLaMA4 中,每个 token 只激活总参数的一部分(称为“活跃参数”)。这使得模型在训练和推理时速度更快,计算成本更低,在相同的计算资源(FLOPs预算)下,MoE 架构通常能比稠密模型达到更好的性能。
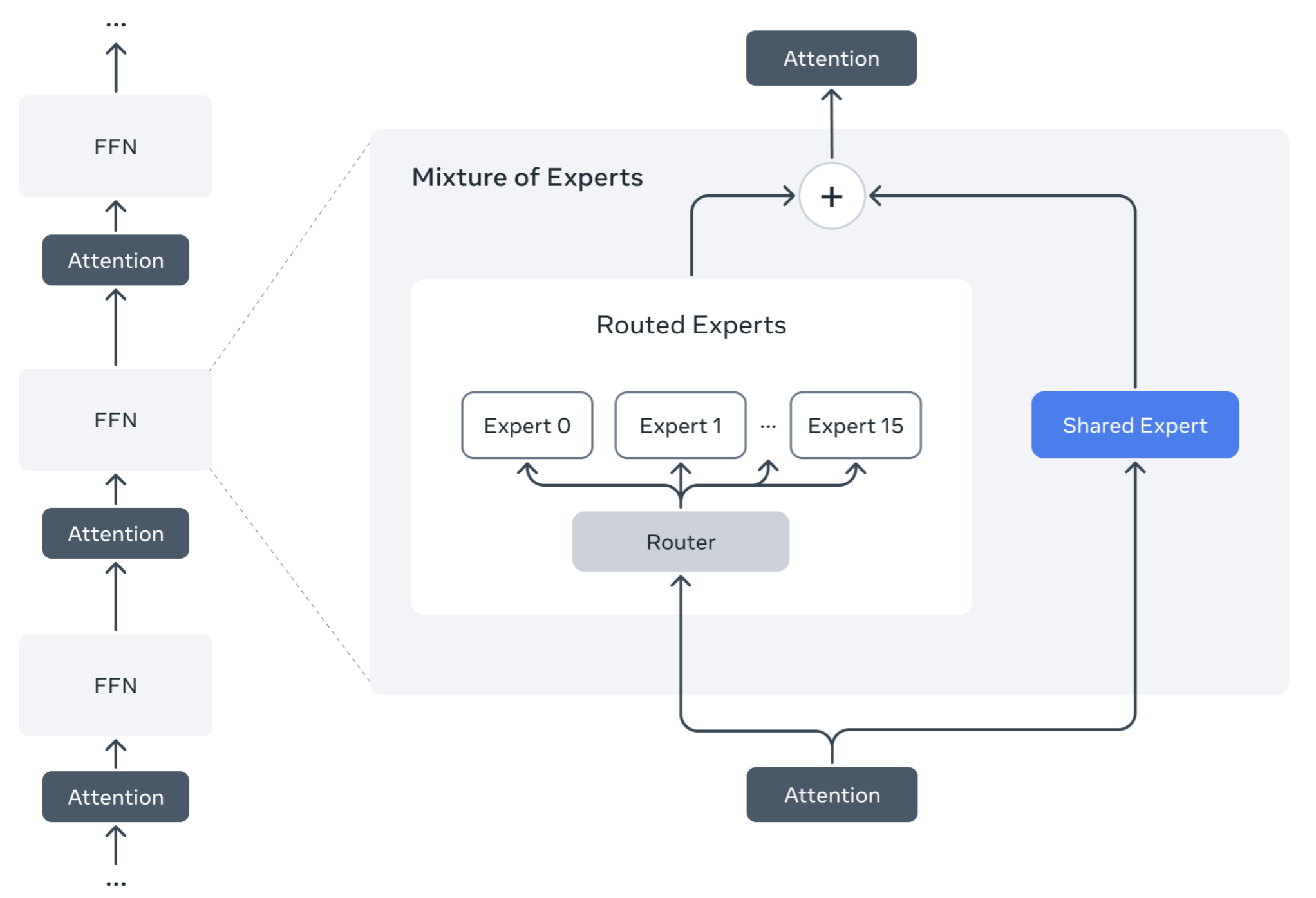
LLaMA4 Maverick版本 使用了 128 个路由专家 和 1 个共享专家。每个 token 会被发送到共享专家,并同时被路由到 128 个专家中的一个进行处理。模型结构上采用了稠密层和 MoE 层交替的方式来进一步优化推理效率。Meta 还特别优化了 MoE 的并行化设计,以提高训练和推理速度。
转向 MoE 是 Llama 4 实现更高性能和效率的关键一步,使得强大的模型(如 Maverick)能够在单个 H100 主机上运行成为可能,并为 Behemoth 这样的超大规模模型训练提供了基础。
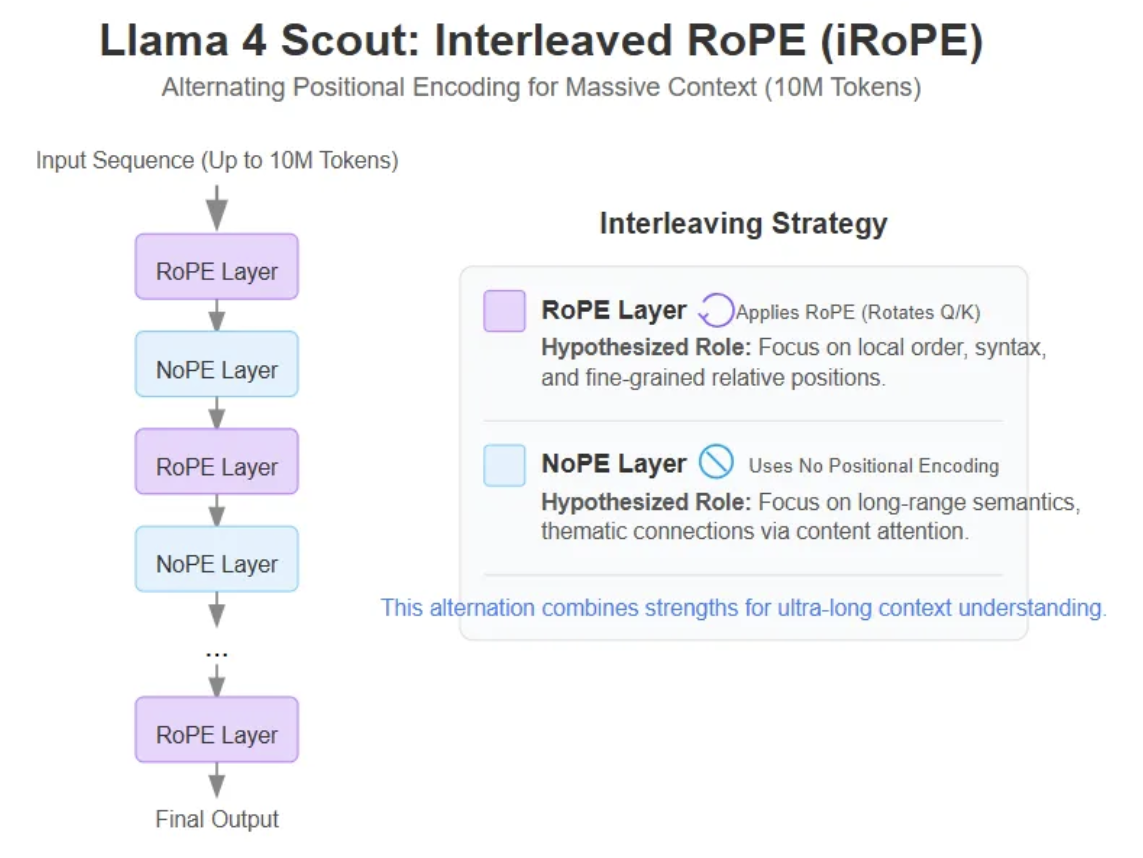
交错注意力层 iRoPE
iRoPE 基于经典的 Rotary Position Embeddings (RoPE),但进行了关键优化:
交错注意力层 (Interleaved Attention Layers):在 Transformer 的注意力层中,标准 RoPE 注意层与 NoPE(无位置编码)层交错使用,即每 4 层中插入 1 层 NoPE(No Positional Embeddings,无位置嵌入) 层,使用全局因果掩码(full causal mask)来捕捉长距离依赖;其余 3 层使用标准的 RoPE 层,结合 chunked attention(分块注意力)来高效处理局部序列。这是支撑“无限”上下文长度的核心设计。
推理时温度缩放(Inference-Time Temperature Scaling):在模型推理阶段动态调整注意力温度参数,进一步增强长度泛化能力(length generalization)。这允许模型在训练时仅使用较短上下文(如 256K token)预训练和后训练,却能推断到远超训练长度的输入,而不会显著损失准确性。
整体架构:RoPE 层负责旋转位置编码(通过旋转查询和键向量注入位置信息),NoPE 层则去除固定位置嵌入,依赖序列内在结构。比例通常为 1 : 3( NoPE : RoPE ),这在 MoE(Mixture of Experts)架构中特别高效,仅激活部分专家参数。
Inside Llama 4: How Meta’s New Open-Source AI Crushes GPT-4o and Gemini